半年ほど放置してしまってました。。
半年ほど、放置してしまってましたが、
サブ商材※として扱っていたVMwareさんの動向が怪しそうだ...という言い訳で、
単純に忙しすぎて放置してた面もありますが、放置しまくりでしたね...反省。
(※本職?元々の仕事はネットワークエンジニアです...)
ひとまず、さらっと、、、
VMwareさんがB社に買収され、perpetualライセンスは無くなり、
Subscriptionだけになる。という話は決まってから1か月たっても変わらないので、
本決まりで良さそうですね。
あとは、エンドユーザをB社が勝手にランク分けして、
大きな会社(エンド)には安い製品売りません的な話も聞きました。。
Consumer:すべて変える
Company:VVFとVCFだけ買える
Storategy:VCFだけ買える
...…
...
なんというか、逆選〇思想な感じも受けますね。。。
うーん、、、
B社において何がミッションで、その為のVisionが何なのか、、、
小職のような凡人には理解できない話なので、
ひとまず、正直、、普通の日本企業には提案できないな...というのが、
感想です。困った。
で、さらっとは出来ない話。
これまでに購入していたPerpetualのライセンスと
subscriptionとを組み合わせるのは…、
出来なくなる様で?(ここ数日でも情報に色々ありました)
メーカ(旧VMwareさん)でもB社に翻弄されて、
営業さんがかわいそうになる位な状況です。
↑エンドユーザから言われた。。。どうしてくれんだ?!
というのを我々も
「いやーメーカーさん(B社)の意向ですからねー
メーカーさんに聞いてみますよー」
と、スルーするから、一番大変なのはVMwareさんの担当なんだろうな...と
思っています。
...……
...
実際、B社に翻弄されて、謝り倒す営業さんのお電話とか頂きますしね...
困りますねー...
ホントに。
そういえば、D社がVMwareさんと元々OEM契約的に話をしていた
VxRail内のライセンスは現状はこのまま提供されるようです。
なので、そこは...「数か月は...キット」安心です。
さておき、そんなこんなで、
別の仕事のネタも探さないといけない!
と、言う所で、
最近、クラウドにも食指を出し始めました。
国内ではシェアは低いですが、AIに強いGoogle Cloudでも、
Professional Cloud Architect...を取得した(できたはず...)ので
今後はそちらの情報発信もしていこうかな...と、思っています。
クラウドの方は、オンプレのようなトラブル...は無い。
と思いますが、、、面白いネタは書いていこうと思います。笑
今回は、ここまでです。
引き続きよろしくお願い致します。
NSXで組むべきネットワーク構成...??①
今回は、
「NSXで組むべきネットワーク構成...??」
というタイトルでお送りします。
前回の投稿では、時間が無かったのでメモ書きとして、
(マニュアルには…絶対に載らない話で、)
この辺こうしたら良いんだろうなーみたいな話を残してましたが、
今回は、その時に組んでみた話で、実際のネットワーク構成について
書いておきます。
個人の見解ではありますが、
ピンポイントで、「こういうことやりたい」ときに
「こういう構成ならできる」という情報って、
すごく役に立つんですよね。
世間では、こういう構成で検証してみました、という話はよく見るのですが、
時間が無いときは、「英和辞書」よりも「和英辞書」的な、
逆引きが出来るようなことがうれしいな。と。
そんなわけで、
・こういうことやりたい:
今回、NSXで「旧Edge Service Gateway(NSX-V)の代わりになるLB」の実装
・やったこと(こういう構成でならできる)
NSXのEdgeにTier1 gatewayを実装して、LBをTier1にサービスとしてホストする
(概念的に?)
この構成を実装するためには、
NSX(NSX-T)のOver-layネットワークを実装する必要があり、
その為には、NSXのEdgeを実装して、
ホストのTEPと通信できるようにしないといけないんですが、
なぜか、EdgeのTEP(overlay用のインタフェース)が
ESXi側のTEPと同一のセグメントでNSXから管理された
ポートグループにいるとトンネルが確立できない※...という
仕様上の問題(バグ??)によって、別セグメントで
構成する必要があります。
※:VMwareでいうクラスタが単一構成だと発生する問題...
とはいえ、日本の企業で管理用の役割だけのホストとして2,3台なんて
構成が組めるユーザなんてほんとに極一部でしょうが・・・。
さておき、NSX-Vのころからのやり方とは、
考え方自体を改めないといけないです。
・Edgeを実装
・Edgeクラスタを実装し、Edgeをメンバにする
・(大規模にしなくて良いなら)T1を作成してサービスIFを作成
・サービスIFにルーティングを設定
・ロードバランサを作成(仮想サーバ、プール、モニタの作成も含む)
(・証明書、SSLの設定)
こんな感じでしょうね。
実際、最小構成・既存ネットワークに極力...
影響・変化を与えずにやるためにはこんな感じです。
TEPが同セグで発生する問題は、前(NSX-T3.x)から聞いてはいたんですが
NSX4.1でもダメっぽいところを見ると、こういう小規模?で発生する問題は
直らない気がしますね。。。
ということで、「既存の環境に影響を与えず」に、
お手軽に別セグにするために構成するお手軽方法!は、
次回、書こうと思います。乞うご期待(?)
今回はここまで。ご参考まで。
NSXの備忘メモ
今回は、情報共有というよりもメモとしての記録です。
(この記事はメモ文を追記して行く形で更新してます。
データセンタ(...避暑地??笑?)内でメモした文章そのままなので、
前後の文章の関係でおかしいところあれば、ご指摘頂ければ幸いです。)
今(リアルタイムで)、まさにNSX4.1を導入してますが、
マネージャ2台だけの構成時に1台落とすと両方こけることがあります。
3台目をデプロイするのが暫く先になるとかいう場合、
1台だけで置いておいた方が良いかな...と、ちょっと思いました。
サクッと3台デプロイしてしまえばいいんですけどね。
(待つだけだし。。)
NSXマネージャ1台目は、
手動でOVFからデプロイすることになると思いますが、
3台構成にした後に1度1台目を消して自動デプロイした方が
綺麗な形になるかなと、思ったり思わなかったり。
↑手動でデプロイしたものはマネージャから消せずに
手で消さないと(vcからディスクから削除で消さないと)いけないんですよね。。。
因みに。
↑やる際に、Managerクラスタのステータスだけ見てたら、
その後、Edgeをデプロイできなくなるという問題を引き当てることになりました。
ステータスが「健全」・グリーンなだけではだめで、
各Managerノードの中(詳細)の
「repo_sync」これがグリーンになってることを確認するべきです。。。
(※各ManagerのREPO_SYNCが赤でもクラスタのステータスはGreenです。。。
バグなんじゃないの??????とは思いますが、
仕様っぽいので、何か作業する際には必ず確認しましょう。)
そんなこんなで、
当ブログを継続して閲覧して頂いている方はお分かりの
「『お』約束」的な障害報告です。
NSX Managerの再デプロイをする際に、
REPO_SYNCが正常になっていない(各ノード(Manager)で同期されていない)
状態になりました。
〇影響(認識していた範囲):
・Edgeノードがデプロイできない
・REPO_SYNCが「失敗」状態になる
〇原因:
マスターノード?のレポジトリが壊れていた
(確認していた事象は2つありましたが、原因は共通です)
ということで!お待ちかねの対応...。
〇対応1:
レポジトリ内で破損しているモジュールの手動復旧...
...
......
コレが、破損しているファイルが少ないなら手っ取り早いので、1番です。
(が、これで終わるわけ無いのが、自分なので。次の対応2に行きました(笑 )
〇対応2:
メーカサポートより提供してもらった、復旧用レポジトリファイルを
レポジトリ領域に展開する。
※サポートに確認してませんが、復旧用ファイルはどこからか
(Customer Connectから)ダウンロードというわけにはいかない様です。
何かあったら、且つ、サポートを頼れる契約でないならば、
次の方法です。
〇対応3(未確認・要注意):
バックアップからリストアしてどうにかする。
.........
......
...
。
冗談でもなんでもなく、こうするしかないですよね?という話ですが、
復元方法としてMANAGERをインストールした上で、
バックアップから復元なので、固有データに関係のないリポジトリは
生き返るはず...です(よね、きっと?)。
※サポートの方からも対応2でうまくいかなければ、
これでやれという指示は頂いたのですが、自分なりに作業の妥当性を
考えるうえでこういう根拠かな?という推察です。
今回はここまで。
メモ書きですが、ご参考まで。
続々・Workspace ONE Accessの脆弱性。。。再び(二度?)
今回は、
「続々・Workspace ONE Accessの脆弱性。。。再び(二度?)」
というタイトルでお送りします。
前回(続・Workspace ONE Accessの脆弱性。。。再び(二度?))からの続きとなります。
前回、
・オフラインバージョンアップがそもそも実行するとエラーになるノードがある
・ノード側のバージョンアップができた後、Elastic Searchが緑にならない
という問題が発生したために持ち越して、
今回再々々トライをしました。
前回の問題を突破するための方法は、以下の通り。
・オフラインバージョンアップがそもそも実行するとエラーになるノードがある
→オフラインバージョンアップをしようとした時に、
ElasticSearchを再indexするか?という質問が出てくるのですが、
クラスタ構成内の2台目以降は再indexしてはいけない様です。。。
※22.09.0.0のマニュアルには1台目と同じ作業を繰り返せという記載だけで、
実は21.08.0.xのマニュアルでは1台目だけ再indexをする様、記載されてます。
Workspace ONE Access クラスタのアップグレード(22.09.0.0)
docs.vmware.com
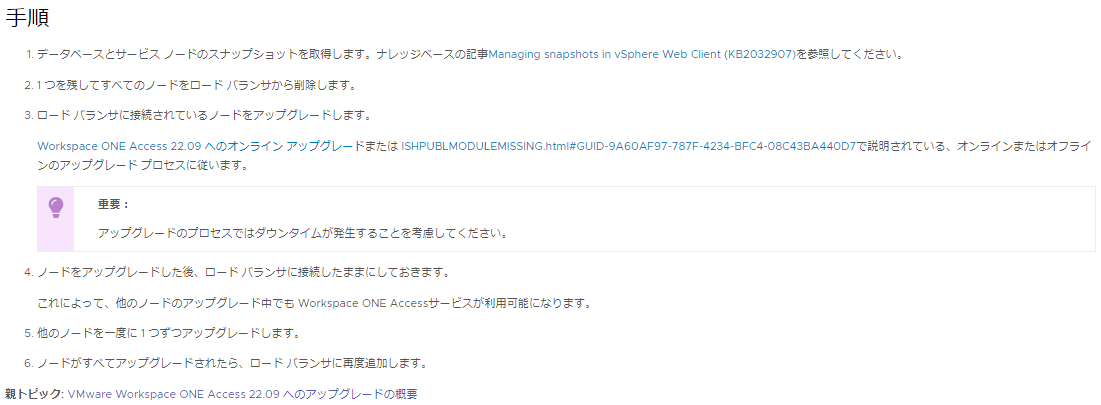
Docs / VMware Workspace ONE Access / VMware Workspace ONE Access 21.08.0.0 へのアップグレード
Workspace ONE Access クラスタのアップグレード(21.08.0.0)

ヒドスギル...
・ノード側のバージョンアップができた後、Elastic Searchが緑にならない
→クラスタ内のノードを全てバージョンアップした後、
未割当のシャードが残存し続けることでステータスが赤のままとなるのが
問題で、対処としては...…『ゴミなら削除。』なのですが……、
削除しても良いかどうかの判断は一般的には言えないので、
メーカサポートにログを送付してください。と...サポートから言われました...。
※Elastic Searchが赤でもサービスには影響無いから↑の対応をしてくれとのことです。
ということで、再々々トライによって、
「今回こそは全台問題なく「予定通り」完了となりました。」
しかも、Elastic Searchもゴミが残らず未割当シャードもゼロとなって
ステータスもグリーンとなり、全て丸く収まった形です!(良い方の想定外)
因みに22.09.0.1では、ElasticsearchはOpensearchに変わってます。
余談ですが…。
ご参考まで。
続・Workspace ONE Accessの脆弱性。。。再び(二度?)
今回は、
「続・Workspace ONE Accessの脆弱性。。。再び(二度?)」
というタイトルでお送りします。
前回(Workspace ONE Accessの脆弱性。。。再び(二度?))からの続きとなります。
前回、オンラインバージョンアップが失敗し、
オフラインバージョンアップをする方向で舵を切り、
手順を整理して、準備万端の(フラグをしっかり立てた)状態にし、
バージョンアップを実行しました。
手順としては以下の通り。
(事前準備として)
VMware様の Customer Connectよりアップグレードに
必要となるファイルをダウンロードしてきます。
・VMware Workspace ONE Access 22.09.0.0内の update-fix.tgz
・VMware Workspace ONE Access 22.09.1.0内の identity-manager-22.09.1.0-20934672-updaterepo.zip
↑をアップデート対象ノードに格納します。
各ノードでは、
まず、update-fix.tgz を解凍し、
configureupdate.hzn を所定の位置に配置し、
権限、所有を調整します。
(以下は update-fix.tgz を /tmp に配置した場合の実行例)
cd /tmp
tar -xvzf update-fix.tgz
cp configureupdate.hzn /usr/local/horizon/update/configureupdate.hzn
chmod 500 /usr/local/horizon/update/configureupdate.hzn
chown root:root /usr/local/horizon/update/configureupdate.hzn
続いて、
オフラインバージョンアップを実施します。
(以下は identity-manager-22.09.1.0-20934672-updaterepo.zip を /tmp に配置した場合の実行例)
/usr/local/horizon/update/updateoffline.hzn -f tmp/identity-manager-22.09.1.0-20934672-updaterepo.zip
オンラインバージョンアップとの違いは、
使用するモジュールとリポジトリファイルを指定する、、、
ということの違いですね。
「ということで、
今回こそは全台問題なく「予定通り」完了となりました。」
となるはずでしたが、(↑前々回の引用)、、
今回もバージョンアップがオフラインでも失敗してしまい、、、
再び持ち越しとなってしまったのです...
今回の問題点としては、
・オフラインバージョンアップがそもそも実行するとエラーになるノードがある
・ノード側のバージョンアップができた後、Elastic Searchが緑にならない
という問題が発生しました、、、
※次回は今回のトラブルシュートまで書ければ…とは考えています。
ご参考まで。
Workspace ONE Accessの脆弱性。。。再び(二度?)
今回は、
「Workspace ONE Accessの脆弱性。。。再び(二度?)」
というタイトルでお送りします。
今回の話題、、、は、これ6月頭、、(公開自体は5/30?)に公開された
今回もソースは、VMware社様のSecurity Advisory (VMSA)です。。。
(※CVE-2023-20884)
『いつも見ていて思うのですが、以前書いた通り攻撃方法であったり、
アクセス可能経路....によって重大度は変わるのですよ。』
うーん、、、(また、)WS1Accessですよ。。。
今回は前回と違って、
前回バージョンアップしたくないの影響が分からないから
メジャーバージョンアップは回避...
したのを今回は、最新の22.09.1.0にバージョンアップした上で
パッチ適用しないといけない様ですね。
今回も自分のユーザ様に関係ある話、、、だったので
脆弱性の情報提供だけでなくて、対応した話まで纏めておきたい、、、
と思い、若干時間が掛かってのお話です。(言い訳(再び...笑 )
昨年(2022年の12月)、脆弱性対応のために
パッチ適用の対応を行ったのですが、
この時は、パッチ適用だけでお茶を濁し対応しました。
さて、、今回(CVE-2023-20884)の対応ですが、、、
現在運用していた21.08.01含め、最新版以外のバージョンに
おいてはパッチが提供されず、最新版にアップデートが必須です。
通常、WS1Accessは複数台でクラスタを構成していると思いますので、
以下の手順で進める必要があります。
(まずはクラスタのバージョンアップ手順)
一台だけをLoad Balancer配下に残し、残したノード一台をバージョンアップします。
その後は、外したノードを1台ずつバージョンアップし、
Load Blancer配下に戻します。
その上で、前回と同様にパッチ適用、、、。
一台ずつクラスタから外してあげて、
パッチ適用して組み込む。そして動作確認。
というのを繰り返すだけです。
「ということで、
パッチ適用については、今回全台問題なく「予定通り」完了となりました。」
となるはずでしたが、(↑前回の引用)、、
そもそものバージョンアップ対応時に、
オンラインバージョンアップが失敗してしまい、、、
翌週(6/18)に持ち越しとなってしまったのです...
原因としては、Accessのノードに設定されている
プロキシの問題の様なのですが、、、
GUIで設定してCLIで設定値を確認しても設定としては入っている…
という状態で、、、調査に時間を掛けて月末に掛かって
運用影響与えるよりもオフラインアップデートを実施する方向としました。。。
※次回はオンラインアップデート、オフラインアップデートのコマンドも含めて書ければ…とは考えています。
ご参考まで。
Horizonのデスクトップを展開した後(数年後に)気が付いたこと
今回は
「Horizonのデスクトップを展開した後(数年後に)気が付いたこと」
というタイトルでお送りします。
今回テーマにするのは、
Horizonに直接関係することではないのですが、
「じぇねらりすと」を自称する人間として
気が付いたことを共有させて頂きます。
Horizonの展開をされるエンジニアの方に
周辺環境として気にして頂ければっていう、お話ですね。
自分もHorizonの仮想デスクトップを実装する中で、
ADはエンドユーザ様に運用であったり、
実装をお任せしてしまうことが多いのですが、
今回問題になったのは、、、
ADに統合されているDNS。。。の部分でした。
仮想デスクトップにおいて、DNSの逆引きが直接影響を与えるということが
無い(はずな)ので、1次DNSサーバとなるADサーバでは
逆引きゾーンを特に用意していない環境だった訳なのですが、
こういう時に、当然デスクトップにIPをLeaseしたDHCPサーバは
ADにレコードを登録できません。(当たり前ですが)
そうしたとき、どういう動きになるかという所で、
リクエストをしている様です。
うーん
大した負荷でもなくこれまで問題になっていませんでしたが、
たまたま2次DNSサーバの方の障害があり、
「何この通信?」となったことで、気が付いたわけです。。。
大した話ではないですが、
フォワーダがInternet上に設定されていたりする場合、
ファイアウォールできちんと切っておかないと余計な通信が
出ていくことになりかねないですね。
ご参考まで。